If your website is on Cloudflare and the HTML is not served from edge cache, your Time to First Byte (TTFB) is probably high for some/many users. High TTFB is bad for user experience and SEO (Core Web Vitals).
There are many ways to solve high TTFB problems on Cloudflare and Speculation Rules is a new option to explore. Speculation Rules is a browser API to prefetch/prerender the page that is likely visited next, and it's coming full to Chrome/Edge browsers soon. Speculation Rules can help speed up any website on any CDN, not just Cloudflare.
This article is a case study of how Speculation Rules improved the TTFB of the CDN Planet website by hundreds of milliseconds for ~20% of pageviews for non-landing pages 🥳
Read on to learn how to improve TTFB on Cloudflare with Speculation Rules.
High TTFB on Cloudflare Workers Sites
The CDN Planet website has many pages (thousands) and a truly global audience. We use Eleventy to generate our static site and push all site resources to Cloudflare using Workers Sites, the predecessor of Cloudflare Pages.
All site resources are stored in Workers KV, Cloudflare's distributed key-value store. The Cloudflare Docs site describes how KV works:
KV is a global, low-latency, key-value data store. It stores data in a small number of centralized data centers, then caches that data in Cloudflare's data centers after access.
...
While reads are periodically revalidated in the background, requests which are not in cache and need to hit the centralized back end can experience high latencies.
And high latencies we have. Our HTML may be stored in edge cache for up to an hour, but due to the long tail nature of our content, users across the globe and Cloudflare's many POP locations, the cache hit ratio for HTML is only ~35% 😞
We measure how long it takes to read the HTML from KV or edge cache from within our Worker: in the past 3 weeks, the daily average 'edge read time' varied between 108 ms and 288 ms and that time goes straight into TTFB and Largest Contentful Paint. That average is based on edge cache reads and reads from KV and assuming edge cache reads are very fast, the average 'KV read time' is surely higher than those 108 and 288 ms.
Cloudflare Pages uses KV as storage/origin too, so this case study is relevant to websites running on Pages too.
Our TTFB on Desktop and Mobile
The Chrome UX Report (known as CrUX) is a public dataset of real user experience data on millions of websites. Data is collected by the Chrome browser on mobile and desktop and is constantly updated. The most talked about data in CrUX are the Core Web Vitals, but there is more, including TTFB.
You can access the CrUX data in many ways. We often use Treo because of the beautiful visualizations.
In September 2023, our TTFB on desktop was 0.4 seconds at the 75th percentile and ~11% of pageviews had a TTFB that Google considers Moderate or Poor. On mobile (second chart below), the TTFB picture looks much worse: TTFB was Moderate or Poor for more than 21% of pageviews. TTFB on mobile is 1.3s at the 90th percentile, meaning 10% of pageviews had a TTFB higher than 1.3 seconds. Ouch.


The CDN Planet website has many users on mobile (43%) and no less than 33% of mobile users are on a slow 3G connection. Improving TTFB is especially important for those 3G users, so what can we do?


Five Ways to Improve TTFB on Cloudflare Workers Sites
Some brainstorming led to five ideas for solving our high TTFB on Cloudflare problem:
| Solution | Thoughts |
|---|---|
| Increase edge cache-control | Easy to implement but unlikely the speed gains are significant |
| Put HTML of popular pages in edge cache | Small code change in our Worker and probably somewhat effective |
| Switch to Cloudflare Pages | Pages uses KV for storage too, so no speed gains expected |
| Use Speculation Rules to prefetch next page | Speculation Rules seems easy to implement, configurable and can do not only prefetch but also full page prerendering |
| Move from KV to multi-region origin | Stop using KV and instead store our static site in multiple datacenters across the globe, using something like Fly.io. Probably very effective, but a big project |
We decided on using Speculation Rules to improve TTFB for our website on Cloudflare, mainly because it allows for starting with prefetch and later upgrading to full page rendering for instant loading of the next page.
Introduction to Speculation Rules
The best place to learn all about the what, why and how of the Speculation Rules API is the Chrome for Developers website where
Barry Pollard, a Web Performance Developer Advocate for Google, published two great articles: Prerender pages in Chrome for instant page navigations and Debugging speculation rules.
I'll provide a brief overview here.
The Speculation Rules API provides a new way for website builders to reduce user-visible latency (= improve TTFB and LCP). The API allows a web page to declare which URLs the user may navigate to next, so the browser can combine this information with its own heuristics to decide whether to speculatively prefetch or prerender pages. The rules are hints and the browser may decide not to act upon them.
The rules are expressed as a JSON object included within a script tag. In the future, the browser may load external rule sets that are served with the Speculation-Rules header. The script tag can statically exist in the page or be dynamically injected by JavaScript.
The prefetched/prerendered page is held in memory and so will be available quicker to the browser once needed. Browsers cache prefetched pages for a short time before discarding them (max 5 minutes in Chrome 118). If the user navigates to the URL while the prefetch/prerender is still in-flight, the browser will use the in-flight fetch/render and continue from there.
Speculation Rules replaces what <link rel="prerender"...> and <link rel="prefetch"...> used to do for preloading navigations.
For now, the API works for same-site speculative loading only.
List Rules
With list rules, the speculation rules JSON contains a list of resources to be fetched, plus options like an explicit Referrer-Policy.
If a resource in the list is not a full, absolute URL, it will be parsed relative to the document base URL.
List rules are supported in Chrome/Edge.
Example of speculation rules using list rules:
<script type="speculationrules">
{
"prerender": [
{
"source": "list",
"urls": ["next.html", "next2.html"]
}
]
}
</script>Document Rules
Instead of List rules, you may also use document rules. These allow the browser to find URLs for speculation from link elements in the page. Document rules allow developers to specify pattern-based allow/deny lists, which is more convenient in scenarios where a page contains a large number of links or dynamic content. Document rules will land in Chrome/Edge mid January 2024 at the earliest, but you can use document rules already on your website by participating in the Origin Trial (more on this below).
Eagerness
You may provide hints about how eagerly the browser should prefetch/prerender links in order to balance the performance advantage against resource overhead.
The value of eagerness may be "conservative", "moderate" or .
If not specified, list rules default to "eager" and document rules default to "conservative".
In Chrome, setting eagerness to moderate means the navigations are prefetched/prerendered when the link is hovered (desktop) or clicked (mobile: touchstart).
Content Security Policy
To allow inline speculation rules in script tags,
use either the 'inline-speculation-rules' or 'unsafe-inline' keyword in the script-src or script-src-elem CSP directives.
The default-src directive can be used to restrict which URLs can be prefetched or prerendered.
Read more about all the (techy) details like anonymous-client-ip-when-cross-origin, window name targeting hints, explicit referrer policy and the No-Vary-Search hint in the Speculation Rules explainer on GitHub, or read the Speculation Rules API reference on MDN
How We Use Speculation Rules
We started using Speculation Rules early October and wanted to use document rules, so we had to participate in the Chrome Origin Trial.
- Read the explainer and spec
- Register for the Chrome Origin Trial
- Create the speculation rules JSON (trial and error, URL patterns != regex)
- Add Origin Trial token and speculation rules JSON to HTML
Origin Trial token in head of HTML:
<meta http-equiv="origin-trial" content="AlGsXbB8btGaaxi/5Py8egKSo1M+A1sTXuTpw2gqIpU9Tm+LCwQzSKJ7PVR5VwuioAz3rD7zwbhg+fG659+UOgYAAABpeyJvcmlnaW4iOiJodHRwczovL3d3dy5jZG5wbGFuZXQuY29tOjQ0MyIsImZlYXR1cmUiOiJTcGVjdWxhdGlvblJ1bGVzUHJlZmV0Y2hGdXR1cmUiLCJleHBpcnkiOjE3MDk2ODMxOTl9">Script with speculation rules JSON in footer:
<script type="speculationrules">
{
"prefetch": [
{
"source": "document",
"where": {
"and": [
{"href_matches": "https:\\/\\/www.cdnplanet.com/*"},
{"not": { "href_matches": "#*" } }
]
},
"eagerness": "moderate"
}
]
}
</script>
We're using document rules and declaring to the browser that it may prefetch any link that starts with https://www.cdnplanet.com/ and is not an in-page link.
The prefetching should happen with moderate eagerness (hover/touch).
It was weird to notice Chrome would prefetch the same page when hovering over an in-page link.
This is now fixed in Chrome 118, so the {"not": { "href_matches": "#*" } } may be removed from the speculation rules.
Knowing there is no harm in leaving it in, that is what we're doing, so Chrome users that have not upgraded to 118 yet are still helped by the prefetching.
Validate Speculation Rules Behaviour
We did not have an Origin Trial token for our dev and staging environments (a mistake) and so could only validate it works in production. Validation of a correct implementation is easy in Chrome Dev Tools:
Open Dev Tools in Chrome and select the Application tab. On the left hand side you'll see a section Preloading. The Speculation rules view should show the number of preloads associated with the rule set that is active on the page. This is confirmation your Speculation Rules are valid and picked up by the browser.
Click on Preloads in the pane on the left to view a list of all URLs the browser may prefetch and each URL's status. Now hover over a link on the page that should trigger a prefetch and sort the Status column (click the column heading twice). At top of the table you'll see the status of the hovered link's URL has changed to Ready.
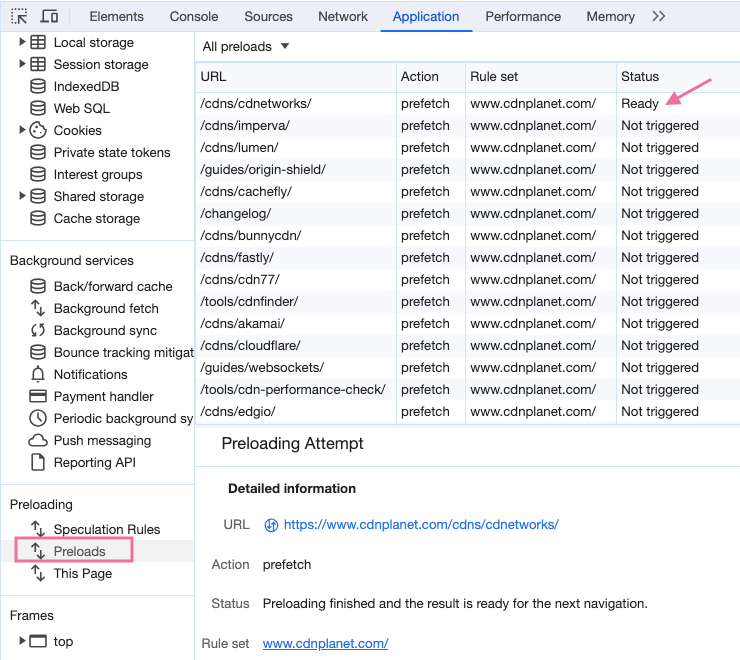
Next, hover over another link to trigger the prefetch and then click that link to navigate to the next page. In Dev Tools, click This Page to view the preloading status.
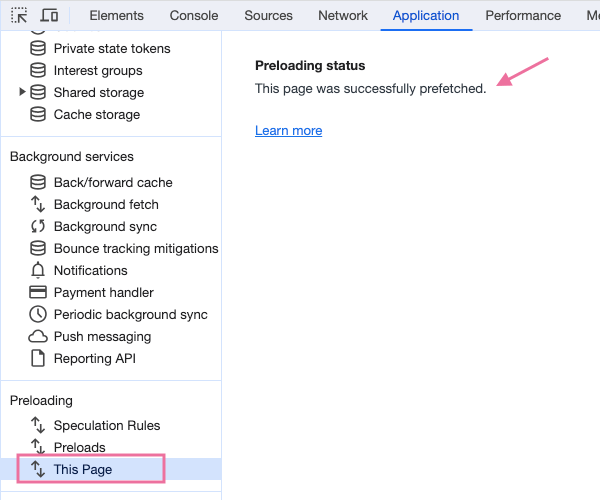
Impact of Speculation Rules on TTFB
The goal is to speed up user experiences by reducing Time to First Byte with prefetching. This translates to two success metrics:
| Metrics | Description |
|---|---|
| Prefetch success ratio | What percentage of eligible pageviews had a prefetched HTML? |
| TTFB Improvement | How much faster did prefetched pages load as a result of lowering TTFB to zero? |
Landing pages and back-forward navigations are logically out of scope. Furthermore, our measurement code ignores page reloads and navigations where the HTML comes from browser cache.
Prefetch success ratio
The percentage of eligible pageviews where the HTML came from the browser's in-memory prefetch cache versus over network was ~15% on mobile and ~22% on desktop 🥳
TTFB Improvement
How much time waiting for the page was saved by the prefetching? Well, prefetched pages have a TTFB of 0 because they are loaded from memory, so we measure the TTFB of non-prefetched pages and assume the TTFB for prefetched pages would have been about the same if those would have loaded without prefetch over network.
The daily average TTFB for non-prefetched pages was between 233 ms and 442 ms, with an outlier of 898 ms on Oct 14.
In conclusion, Speculation Rules prefetch improved TTFB on our Cloudflare Workers website by ~300 ms for ~20% of eligible pageviews. That's a good win, but we want to do better, so we'll continue to look into ways to improve TTFB and consequently FCP and LCP.
How We Measured Effects of Speculation Rules
In short:
- The Cloudflare Worker script measures how long it takes to read HTML from edge cache or KV (edge read time) and exposes this to the browser in a Server-Timing header
- JS in our pages gets the TTFB and Prefetched (yes/no) from the browser's built-in Performance API, as well as the edge read time
- The slightly modified JS snippet for Google Analytics adds the metrics as custom parameters to the
page_viewevent
The edge read time is not required to measure effectiveness of speculation rules, but we useful to understand what % of TTFB is made up of reading the resource from edge case or KV.
Keep an eye out for our upcoming blog post with all the details on how we are tracking effectiveness of speculation rules in Google Analytics.
Cloudflare's Prefetch URLs vs Speculation Rules
Cloudflare has a feature for Enterprise customers that pulls content from the origin into the edge cache.
URL prefetching means that Cloudflare pre-populates the cache with content a visitor is likely to request next. This setting — when combined with additional setup — leads to a higher cache hit rate and thus a faster experience for the user.
Surely some customers will find this useful, but it does not prefetch HTML and you need to supply a static list of files to prefetch. Read more in the docs for Cloudflare Prefetch URLs.
Cloudflare Prefetch URLs is for prefetching website resources from origin to edge cache, while Speculation Rules prefetches HTML from edge cache to browser.
Learnings & Tips
- Documentation is good. The articles on developer.chrome.com are great and the explainer provides more details/background where needed
- The Network tab in Dev Tools signifies if a document was prefetched sucessfully: the Size column shows
(prefetch cache) - Getting the document rules right may take some time (URL patterns can be hard)
- It's recommended to register your dev/staging env for the Origin Trial too, so you can validate it all works well before pushing to production
- Good to know: early hints delivered for prefetched documents won't be processed by the browser
Questions? Feedback? Send it our way on Twitter / X. We'd also love to hear about your experiences using the Speculation Rules API.
Speculation Rules FAQ
- Which browsers support the Speculation Rules API?
- Can I feature detect the Speculation Rules API?
- Is it possible to detect prefetched and prerendered pages?
- Is it safe to prefetch or prerender any page?
- How long does Chrome keep a prefetched/prerendered page in memory?
- How many prefetched/prerendered pages can Chrome keep in memory?
Which browsers support the Speculation Rules API?
As of October 2023, the Speculation Rules API is supported in Chrome and Edge browsers version 109 and up and Opera 95. Certain features and options, including document rules, are landing in Chrome/Edge 120.
Browser compatibility table on MDN
Can I feature detect the Speculation Rules API?
Yes, use JavaScript to check if HTMLScriptElement supports "speculationrules".
Speculation rules API feature detection (MDN)
Is it possible to detect prefetched and prerendered pages?
You can detect prefetched and prerendered pages server-side based on the Sec-Purpose request header. In the browser, use JavaScript to detect if a page was prefetched, prerendered or even if the page is being prerendered.
Detecting prefetched and prerendered pages (MDN)
Is it safe to prefetch or prerender any page?
No, under certain conditions it is unsafe to prefetch/prerender. For example, prefetching a page whose server-generated content depends on what the user does on the current page is potentially risky and could lead to confused users.
Unsafe speculative loading conditions (MDN)
How long does Chrome keep a prefetched/prerendered page in memory?
The Chrome browser keeps prefetched/prerendered pages in memory for up to 5 minutes.
How many prefetched/prerendered pages can Chrome keep in memory?
The limit is 5 for prefetched pages and 10 for prerendered pages.